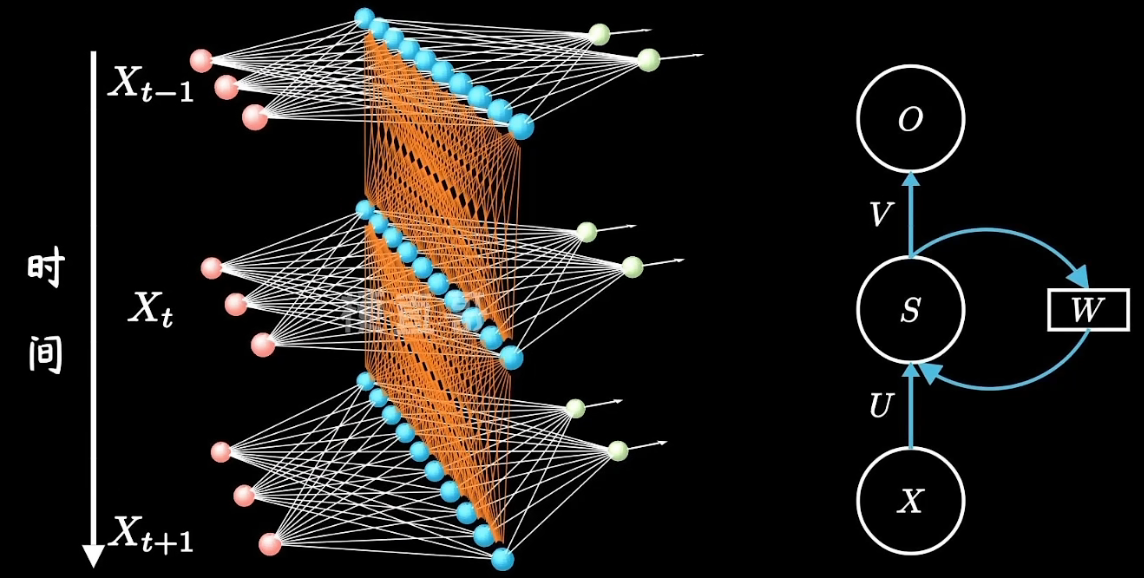
RNN对两个时刻的隐藏层进行了连接,使得神经网络具有记忆功能。

LSTM 讲解:【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑
LSTM相较于RNN增加了一条新的时间链:





实际上,LSTM的网络是这样的:

上面的图表示包含2个隐含层的LSTM网络,在T=1时刻看,它是一个普通的BP网络,在T=2时刻看也是一个普通的BP网络,只是沿时间轴展开后,T=1训练的隐含层信息H,C会被传递到下一个时刻T=2,如下图所示。上图中向右的五个长长的箭头,说的也是隐含层状态在时间轴上的传递。
使用深度学习进行时间序列预测
此示例说明如何使用长期短期记忆 (LSTM) 网络预测时间序列数据。
LSTM 网络是一种循环神经网络 (RNN),它通过遍历时间步并更新 RNN 状态来处理输入数据。RNN 状态包含在所有先前时间步中记住的信息。您可以使用 LSTM 神经网络,通过将先前的时间步作为输入来预测时间序列或序列的后续值。要为时间序列预测训练 LSTM 神经网络,请训练具有序列输出的回归 LSTM 神经网络,其中响应(目标)是将值移位了一个时间步的训练序列。也就是说,在输入序列的每个时间步,LSTM 神经网络都学习预测下一个时间步的值。
有两种预测方法:开环预测和闭环预测。
- 开环预测仅使用输入数据预测序列中的下一个时间步。对后续时间步进行预测时,需要从数据源中收集真实值并将其用作输入。例如,假设您要使用时间步 1 到 t−1 中收集的数据来预测序列的时间步 t 的值。要对时间步 t+1 进行预测,请等到记录下时间步 t 的真实值,并将其用作输入进行下一次预测。在进行下一次预测之前,如果有可以提供给 RNN 的真实值,则请使用开环预测。
- 闭环预测通过使用先前的预测作为输入来预测序列中的后续时间步。在这种情况下,模型不需要真实值便可进行预测。例如,假设您要仅使用在时间步 1 至 t−1 中收集的数据来预测序列的时间步 t 至 t+k 的值。要对时间步 i 进行预测,请使用时间步 i−1 的预测值作为输入。使用闭环预测来预测多个后续时间步,或在进行下一次预测之前没有真实值可提供给 RNN 时使用闭环预测。
指定训练数据
首先,你需要将所有数据分成三个部分(当然可以不要验证集,一般论文里我们是返回验证集上的最优模型):训练集、验证集和测试集,也就是把3000行数据分成三部分,一般是622或者712,这里以622为例,也就是说训练集中有1800条数据,验证集和测试集各600条数据。
然后你需要对训练集中的数据进行归一化,例如最大最小值归一化,然后假设你使用前100个数据预测接下来10个数据(比如你可以用前100个数据的300个特征预测接下来10个数据的某一个或者某几个特征,例如你可以用前100个时刻的ABCDE特征预测接下来10个时刻的A特征或者10个时刻的ABC特征,这里以10个A特征为例),那么此时你构建的第1个样本应该为(X=1…100,Y=101…110),第二个样本为(X=2…101,Y=102…111),最后一个样本为(X=1691…1790 Y=1791…1800)。
这样,你的训练集中一个包含了1691个样本,然后你就可以进一步进行分批处理。分批处理前你可以打乱这1691个样本,这种打乱是不会对LSTM的训练造成影响的,因为每个样本的内部是有序的,LSTM处理的是这100个数据间的时序关系。但是如果你用sgd或者minibatch,一般来讲靠前的batch会对模型梯度造成更大影响,为了公平起见,可以选择打乱数据。
打乱数据后就可以开始进行批次处理,比如batch_size=100,也就是将1691个样本每100个分为一组,这样你一共可以得到17个batch的数据,除了最后一个bacth的X为(batch_size=91,seq_len=100, input_size=5),Y为(batch=91, output_size=1)以外,其他16个batch的X为(batch_size=100,seq_len=100, input_size=5),Y为(batch=100, output_size=1)。
准备要填充的数据
在训练过程中,默认情况下,软件将训练数据拆分成小批量并填充序列,使它们具有相同的长度。过多填充会对网络性能产生负面影响。
为了防止训练过程添加过多填充,您可以按序列长度对训练数据进行排序,并选择合适的小批量大小,以使同一小批量中的序列长度相近。下图显示了对数据进行排序之前和之后填充序列的效果。

定义 LSTM 神经网络架构
创建一个 LSTM 回归神经网络。
- 使用输入大小与输入数据的通道数匹配的序列输入层。
- 接下来,使用一个具有 128 个隐藏单元的 LSTM 层。隐藏单元的数量确定该层学习了多少信息。使用更多隐藏单元可以产生更准确的结果,但也更有可能导致训练数据过拟合。
- 要输出通道数与输入数据相同的序列,请包含一个输出大小与输入数据通道数匹配的全连接层。
- 最后,包括一个回归层。
1 | layers = [ |
- 批归一化在每一层中用于减少内部协变量移位。
- Dropout使神经元以一定概率丢失,以防止每个隐藏层后面的过拟合问题。
LSTM 层架构
下图说明具有 C 个长度为 S 的特征(通道)的时序 X 通过 LSTM 层的流程。在图中,ht 和 ct分别表示在时间步 t 的输出(也称为隐藏状态)和 单元状态。

第一个 LSTM 模块使用网络的初始状态和序列的第一个时间步来计算第一个输出和更新后的单元状态。在时间步 t 上,该模块使用网络的当前状态 (ct−1,ht−1) 和序列的下一个时间步来计算输出和更新后的单元状态 ct。
该层的状态由隐藏状态(也称为输出状态)和单元状态组成。时间步 t 处的隐藏状态包含该时间步的 LSTM 层的输出。单元状态包含从前面的时间步中获得的信息。在每个时间步,该层都会在单元状态中添加或删除信息。该层使用不同的门控制这些更新。
指定训练选项
指定训练选项。
- 使用 Adam 优化进行训练。
- 进行 200 轮训练。对于较大的数据集,您可能不需要像良好拟合那样进行这么多轮训练。
- 在每个小批量中,对序列进行左填充,使它们具有相同的长度。左填充可以防止 RNN 预测序列末尾的填充值。
- 每轮训练都会打乱数据。
- 在绘图中显示训练进度。
禁用详细输出。
matlab中在对LSTM进行训练时需要明确是sequence to sequence还是sequence to last。前者是在每一个时间步都进行预测,后者是只在最后一个时间步进行预测,详细请参考matlab文档说明。EMG-force的回归主要用到sequence to sequence。
一些评论:
——看了不少LSTM简单实例,发现都是滚动预测。宣称预测后三年数据,其实每次只能预测后一个月的数据,我称之为假 · 预测。
——您好,用神经网络做预测的时候,目前大多是都只预测下一个时间步的,如果需要长时预测(例如预测未来3s的车辆轨迹),那就需要滚动预测或者迭 代了。您有不同的见解挺好的,可以麻烦提供新的思路以做讨论吗,谢谢!
——可以看看seq2seq、注意力机制还有transformer之类的,我看的李沐和李宏毅的讲解。虽然我目前还是做的滚动预测,不过可以一次输出多个时间 步然后再滚动。遇到的问题就是这种复杂模型因为各种原因不一定有效果,比如数据量不够,只能说是值得一试。